Google Dorking або використовуємо Google на максимум
За Хабр26 хв
Google Dorks або Google Hacking — техніка, що використовується ЗМІ, слідчими органами, інженерами з безпеки та будь-якими користувачами для створення запитів у різних пошукових системах для виявлення прихованої інформації та вразливостей, які можна знайти на загальнодоступних серверах. Це спосіб, у якому звичайні запити на пошук веб-сайтів використовуються в повну міру для визначення інформації, прихованої на поверхні.
Як працює Google Dorking?
Даний приклад збору та аналізу інформації, що виступає як інструмент OSINT, є не вразливістю Google та не пристроєм для злому хостингу сайтів. Навпаки, він виступає у ролі простого пошукового процесу даних із розширеними можливостями. І це не в новинку, тому що існує безліч веб-сайтів, яким вже більше десятка років і вони служать як сховища для вивчення та використання Google Hacking.
У той час як пошукові системи індексують, зберігають хедери та вміст сторінок, та пов'язують їх між собою для оптимальних пошукових запитів. Але на жаль, мережні павуки будь-яких пошукових систем налаштовані індексувати абсолютно всю знайдену інформацію. Навіть незважаючи на те, що адміністратори веб ресурсів не мали жодних намірів публікувати цей матеріал.
Однак найцікавіше в Google Dorking, так це величезний обсяг інформації, який може допомогти кожному у процесі вивчення пошукового процесу Google. Може допомогти новачкам у пошуку зниклих родичів, а може навчити, яким чином можна отримати інформацію для власної вигоди. Загалом кожен ресурс цікавий і дивовижний за своїм і може допомогти кожному в тому, що саме він шукає.
Яку інформацію можна знайти за допомогою Dorks?
Починаючи від контролерів віддаленого доступу різних заводських механізмів до конфігураційних інтерфейсів важливих систем. Є припущення, що величезну кількість інформації, викладеної в мережі, ніхто і ніколи не знайде.
Однак, давайте розберемося по порядку. Уявіть нову камеру відеоспостереження, яка дозволяє переглядати її трансляцію на телефоні в будь-який час. Ви налаштовуєте та підключаєтеся до неї через Wi-Fi, і завантажуєте програму для автентифікації входу в систему камери спостереження. Після цього можна отримати доступ до цієї камери з будь-якої точки світу.
На задньому плані не все виглядає таким простим. Камера надсилає запит на китайський сервер та відтворює відео в режимі реального часу, дозволяючи увійти в систему та відкрити відеотрансляцію, розміщену на сервері у Китаї, з вашого телефону. Цей сервер може не вимагати пароля для доступу до каналу з вашої веб-камери, що робить її загальнодоступною для всіх, хто шукає текст, який міститься на сторінці перегляду камери.
І на жаль, Google безжально ефективний у пошуку будь-яких пристроїв в Інтернеті, що працюють на серверах HTTP та HTTPS. І оскільки більшість цих пристроїв містять певну веб платформу для їх налаштування, це означає, що багато речей, не призначених бути в Google, зрештою опиняються там.
Безумовно, найсерйозніший тип файлів, це той, який несе в собі облікові дані користувачів або всієї компанії. Зазвичай це відбувається двома способами. У першому сервер налаштований неправильно і виставляє свої адміністративні логи або журнали у відкритому доступі в Інтернеті. Коли паролі змінюються або користувач не може увійти до системи, ці архіви можуть витекти з обліковими даними.
Другий варіант відбувається тоді, коли конфігураційні файли, що містять ту саму інформацію (логіни, паролі, назви баз даних і т.д.), стають загальнодоступними. Це файли повинні бути обов'язково приховані від будь-якого публічного доступу, оскільки вони часто залишають важливу інформацію. Будь-яка з цих помилок може призвести до того, що зловмисник знайде дані лазівки та отримає всю потрібну інформацію.
Ця стаття ілюструє використання Google Dorks, щоб показати не тільки як знаходити всі ці файли, але й наскільки бувають вразливі платформи, що містять інформацію у вигляді списку адрес, електронної пошти, картинок і навіть переліку веб-камер у відкритому доступі.
Розбір операторів пошуку
Dorking можна використовувати в різних пошукових системах, не лише Google. У повсякденному використанні пошукові системи, такі як Google, Bing, Yahoo та DuckDuckGo, приймають пошуковий запит або рядок пошукових запитів та повертають відповідні результати. Також ці системи запрограмовані приймати більш просунуті і складніші оператори, які значно звужують ці умови пошуку. Оператор - це ключове слово або фраза, що має особливе значення для пошукової системи. Ось приклади операторів, що часто використовуються: "inurl", "intext", "site", "feed", "language". За кожним оператором слідує двокрапка, за якою слідує відповідна ключова фраза або фрази.
Ці оператори дозволяють шукати більш конкретну інформацію, наприклад: певні рядки тексту всередині сторінок веб-сайту або файли, розміщені за конкретною URL-адресою. Крім того, Google Dorking може також знаходити приховані сторінки для входу в систему, повідомлення про помилки, що видають інформацію про доступні вразливості та файли загального доступу. В основному причина полягає в тому, що адміністратор веб-сайту міг просто забути виключити з відкритого доступу.
Найбільш практичним і водночас цікавим сервісом Google є можливість пошуку віддалених або архівних сторінок. Це можна зробити за допомогою оператора cache:. Оператор працює таким чином, що показує збережену (віддалену) версію веб-сторінки, що зберігається в кеш-Google. Синтаксис цього оператора показаний тут:

кеш: www.youtube.com
Після виконання вищевказаного запиту в Google надається доступ до попередньої або застарілої версії веб-сторінки Youtube. Команда дозволяє викликати повну версію сторінки, текстову версію або саме джерело сторінки (цілісний код). Вказується точний час (дата, година, хвилина, секунда) індексації, зробленої павуком Google. Сторінка відображається у вигляді графічного файлу, хоч і пошук по самій сторінці здійснюється так само, як у звичайній сторінці HTML (поєднання клавіш CTRL + F). Результати виконання команди cache: залежать від того, як часто веб-сторінка індексувалася роботом Google. Якщо розробник сам встановлює індикатор із певною частотою відвідувань у заголовку HTML-документа, то Google розпізнає сторінку як другорядну і зазвичай ігнорує її на користь коефіцієнта PageRank, є основним чинником частоти індексації сторінки. Тому, якщо конкретна веб-сторінка була змінена, між відвідуваннями робота Google вона не буде проіндексована і не буде прочитана за допомогою команди «cache:». Приклади, які особливо добре працюють при тестуванні цієї функції, є блоги, облікові записи соціальних мереж та інтернет-портали, що часто оновлюються.
Видалену інформацію або дані, які були помилково розміщені або вимагають видалення в певний момент, можна дуже легко відновити. Недбалість адміністратора веб-платформ може поставити його під загрозу поширення небажаної інформації.
Інформація про користувачів
Пошук інформації про користувачів використовується за допомогою розширених операторів, які роблять результати пошуку точними та детальними. Оператор "@" використовується для пошуку індексації користувачів у соціальних мережах: Twitter, Facebook, Instagram. На прикладі того самого польського вишу, можна знайти його офіційного представника, на одній із соціальних платформ, за допомогою цього оператора наступним чином:

inurl: twitter @minregion_ua
Цей запит на Twitter знаходить користувача «minregion_ua». Припускаючи, що місце або найменування роботи користувача, якого шукаємо (Міністерство з розвитку громад та територій України) та його ім'я відомі, можна поставити більш конкретний запит. І замість стомлюючого пошуку по всій веб-сторінці закладу, можна задати правильний запит на основі адреси електронної пошти і припустити, що в назві адреси має бути вказано хоча б ім'я користувача або установи, що запитується. Наприклад:

сайт: www.minregion.gov.ua «@minregion.ua»
Можна також використовувати менш складний метод і надіслати запит тільки за адресами електронної пошти, як показано нижче, сподіваючись на удачу та нестачу професіоналізму адміністратора веб ресурсу.

email.xlsx
Тип файлу: xls + email
До того ж можна спробувати отримати адреси електронної пошти з веб-сторінки за таким запитом:

site:www.minregion.gov.ua intext:e-mail
Зазначений вище запит буде здійснювати пошук за ключовим словом «email» на веб-сторінці Міністерства розвитку громад та територій України. Пошук адрес електронної пошти має обмежене використання і в основному вимагає невеликої підготовки та збору інформації про користувачів заздалегідь.
На жаль, пошук індексованих телефонних номерів через phonebook Google обмежений лише на території США. Наприклад:

телефонна книга: Артур Мобільний AL
Пошук інформації про користувачів також можливий через Google image search або зворотного пошуку зображень. Це дозволяє знайти ідентичні або схожі фотографії на сайтах, проіндексованих Google.
Інформація веб-ресурсів
Google має кілька корисних операторів, зокрема related:, який відображає список схожих веб-сайтів на потрібний. Подібність полягає в функціональних посиланнях, а чи не на логічних чи змістовних зв'язках.
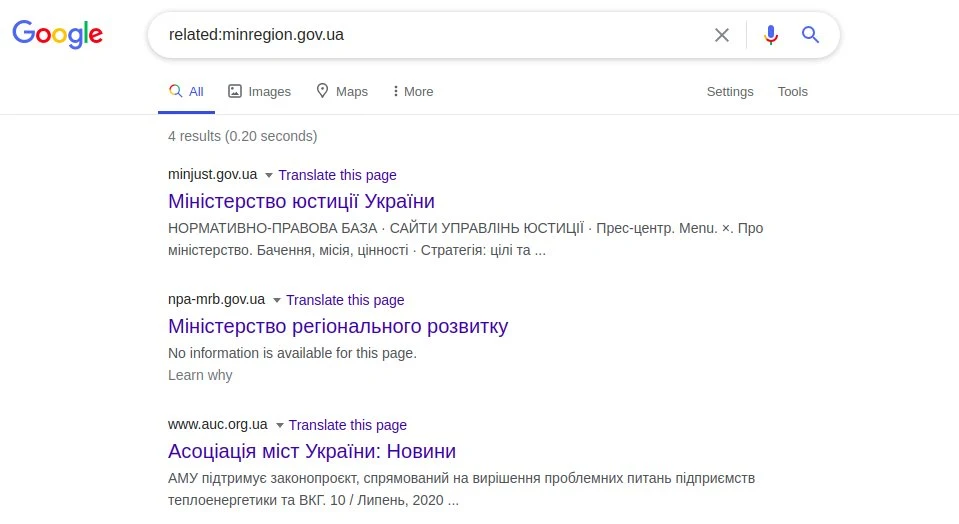
за темою: minregion.gov.ua
На цьому прикладі відображаються сторінки інших Міністерств України. Цей оператор працює як кнопка "Схожі сторінки" у розширеному пошуку Google. Так само працює запит “info:”, який відображає інформацію на певній веб-сторінці. Це конкретна інформація веб-сторінки, представлена в заголовку веб-сайту (), а саме мета-тегах опису (<meta name = “Description”). Приклад:
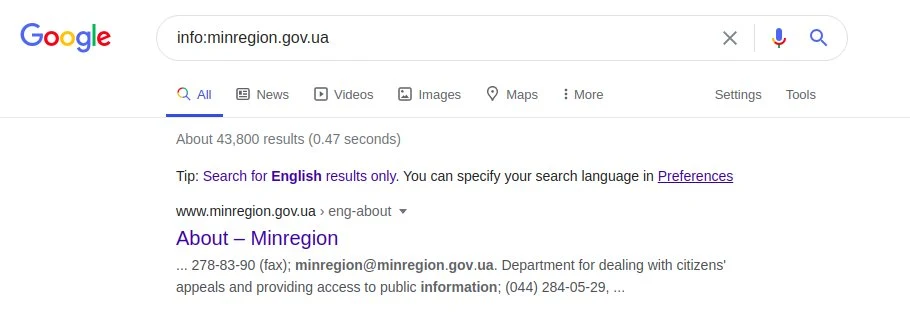
info:minregion.gov.ua
Інший запит, "define:" дуже корисний у пошуку наукової роботи. Він дозволяє отримати визначення слів із таких джерел, як енциклопедій та онлайн-словників. Приклад його застосування:

визначити: території України
Універсальний оператор - тильда ("~"), дозволяє шукати схожі слова або слова синоніми:

~громад ~розвитку
Наведений вище запит відображає як веб-сайти зі словами «громад» (територій) та «розвитку» (розвиток), так і сайти із синонімом «громади». Оператор «link:», який модифікує запит, обмежує діапазон пошуку посиланнями, вказаними для певної сторінки.

link:www.minregion.gov.ua
Однак цей оператор не відображає всі результати та не розширює критерії пошуку.
Хештеги є своєрідними ідентифікаційними номерами, що дозволяють групувати інформацію. В даний час вони використовуються в Instagram, VK, Facebook, Tumblr та TikTok. Google дозволяє шукати в багатьох соціальних мережах одночасно або тільки в рекомендованих. Приклад типового запиту до будь-якої пошукової системи є:

#політикавукраїні
Оператор AROUND(n) дозволяє шукати два слова, розташовані на відстані певної кількості слів, один від одного. Приклад:

Міністерство AROUND(4) України
Результатом вищезгаданого запиту є відображення веб-сайтів, які містять ці два слова ("міністерство" та "України"), але вони відокремлені один від одного чотирма іншими словами.
Пошук за типами файлів також надзвичайно корисний, оскільки Google індексує матеріали відповідно до їх форматів, у яких вони були записані. Для цього використовується оператор "filetype:". В даний час використовується широкий діапазон пошуку файлів. Серед усіх доступних пошукових систем Google надає найскладніший набір операторів для пошуку відкритих вихідних кодів.
Як альтернатива вищезгаданих операторів, рекомендуються такі інструменти, як Maltego та Oryon OSINT Browser. Вони забезпечують автоматичний пошук даних та не вимагають знання спеціальних операторів. Механізм програм дуже простий: за допомогою правильного запиту, направленого в Google або Bing, знаходяться документи, опубліковані установою, що вас цікавить, і аналізуються метадані з цих документів. Потенційним інформаційним ресурсом для таких програм є кожен файл з будь-яким розширенням, наприклад: ".doc", ".pdf", ".ppt", ".odt", ".xls" або ".jpg".
Додатково слід сказати про те, як правильно подбати про «очищення своїх метаданих», перш ніж робити файли загальнодоступними. У деяких веб-посібниках передбачено щонайменше кілька способів позбавлення від мета інформації. Однак неможливо вивести найкращий спосіб, тому що це все залежить від індивідуальних уподобань самого адміністратора. В основному рекомендується записати файли у форматі, в якому спочатку не зберігаються метадані, а потім зробити файл доступним. В Інтернеті є багато безкоштовних програм очищення метаданих, головним чином, щодо зображень. ExifCleaner може розглядатися як один із найбажаніших. У разі текстових файлів рекомендується виконувати очищення вручну.
Інформація, несвідомо залишена власниками сайтів
Ресурси, що індексуються Google, залишаються публічними (наприклад внутрішні документи та матеріали компанії, що залишилися на сервері), або вони залишаються для зручності використання тими самими людьми (наприклад, музичні файли або файли фільмів). Пошук такого контенту може бути зроблений за допомогою Google через безліч різних способів і найпростіший з них це просто вгадати. Якщо наприклад у певному каталозі є файли 5.jpg, 8.jpg і 9.jpg, можна передбачити, що є файли від 1 до 4, від 6 до 7 і навіть більше 9. Тому можна отримати доступ до матеріалів, які не повинні були у публічному вигляді. Інший спосіб – пошук за певними типами контенту на веб-сайтах. Можна шукати музичні файли, фотографії, фільми та книги (електронні книги, аудіокниги).
В іншому випадку це можуть бути файли, які користувач залишив несвідомо у публічному доступі (наприклад музика на FTP сервері для власного використання). Таку інформацію можна отримати двома способами: використовуючи оператор "filetype:" або оператор "inurl:". Наприклад:

filetype:doc site:gov.ua
site:www.minregion.gov.ua filetype:pdf
site:www.minregion.gov.ua inurl:doc
Також можна шукати програмні файли, використовуючи пошуковий запит і фільтруючи шуканий файл для його розширення:

тип файлу: iso
Інформація про структуру веб-сторінок
Для того щоб переглянути структуру певної веб-сторінки та розкрити всю її конструкцію, яка допоможе надалі сервера та його вразливості, можна зробити це, використовуючи лише оператор «site:». Давайте проаналізуємо таку фразу:

site: www.minregion.gov.ua minregion
Ми розпочинаємо пошук слова «minregion» в домені «www.minregion.gov.ua». Кожен сайт із цього домену (Google шукає як у тексті, в заголовках та в заголовку сайту) містить це слово. Таким чином, отримуючи повну структуру всіх сайтів цього конкретного домену. Як тільки структура каталогів стане доступною, точніший результат (хоча це не завжди може статися) можна отримати за допомогою наступного запиту:

site:minregion.gov.ua intitle:index.of «батьківський каталог»
Він показує найменш захищені субдомени «minregion.gov.ua», іноді з можливістю пошуку по всьому каталогу, разом із можливим завантаженням файлів. Тому, звичайно, такий запит не застосовується до всіх доменів, оскільки вони можуть бути захищені або працювати під керуванням іншого сервера.


site:gov inurl:robots.txt intext:Disallow: /web.config
Цей оператор дозволяє отримати доступ до параметрів конфігурацій різних серверів. Після проведення запиту, переходимо у файл robots.txt, шукаємо шлях до «web.config» та перехід по заданому шляху файлу. Щоб отримати ім'я сервера, його версію та інші параметри (наприклад, порти), робиться наступний запит:

site:gosstandart.gov.by intitle:index.of server.at
Кожен сервер має свої унікальні фрази на великих сторінках, наприклад, Internet Information Service (IIS):

intitle:welcome.to intitle:internet IIS
Визначення самого сервера і використовуваних у ньому технологій залежить тільки від винахідливості запиту, що задається. Можна, наприклад, спробувати це зробити за допомогою уточнення технічної специфікації, керівництва або так званих сторінок довідок. Щоб продемонструвати цю можливість, можна скористатися таким запитом:

site:gov.ua inurl:ручні модулі директив apache (Apache)
Доступ може бути розширеним, наприклад, завдяки файлу з помилками SQL:

Тип файлу «#mysql dump»: SQL
Помилки в базі даних SQL можуть, зокрема, надати інформацію про структуру та зміст баз даних. У свою чергу, вся веб-сторінка, її оригінал та (або) її оновлені версії можуть бути доступні за таким запитом:
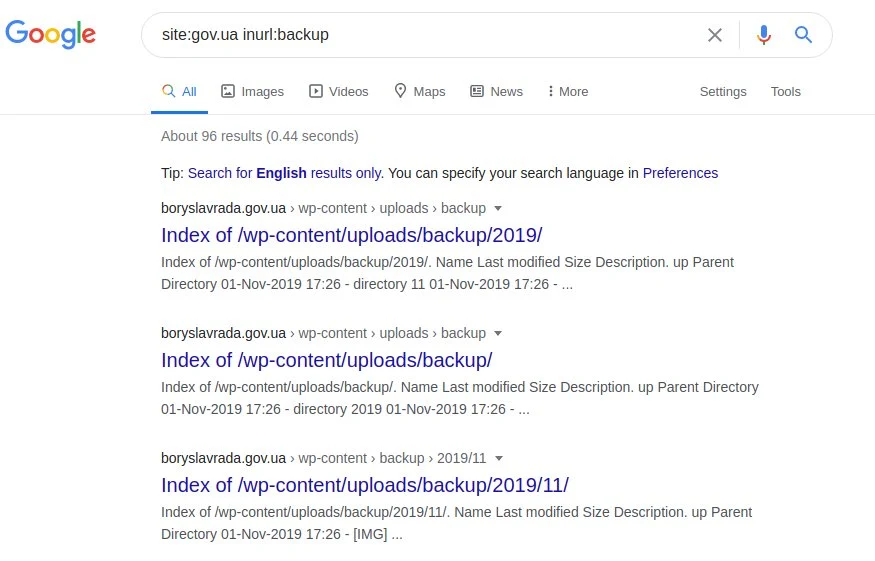
сайт: gov.ua inurl: бекап
site:gov.ua inurl:резервна копія intitle:index.of inurl:admin
В даний час використання вищезгаданих операторів досить рідко дає очікувані результати, оскільки вони можуть бути заздалегідь заблоковані обізнаними користувачами.
Також за допомогою програми FOCA можна знайти такий самий контент, як і при пошуку вищезгаданих операторів. Для початку роботи, програмі потрібна назва доменного імені, після чого вона проаналізує структуру всього домену та всіх інших піддоменів, підключених до серверів конкретної установи. Таку інформацію можна знайти у діалоговому вікні на вкладці «Мережа»:

Таким чином, потенційний зловмисник може перехопити дані, надані веб-адміністраторами, внутрішні документи та матеріали компанії, залишені навіть на прихованому сервері.
Якщо ви захочете дізнатися більше інформації про всіх можливих операторів індексування ви можете ознайомитися з цільовою базою даних усіх операторів Google Dorking ось тут . Також можна ознайомитися з одним цікавим проектом на GitHub, який зібрав у себе всі найпоширеніші та найвразливіші URL посилання та спробувати пошукати для себе щось цікаве, його можна подивитися ось за цим посиланням .
Комбінуємо та отримуємо результати
Для більш конкретних прикладів, нижче представлена невелика збірка з операторів Google, які часто використовуються. У комбінації різної додаткової інформації і тих же команд, результати пошуку показують більш докладний погляд на процес отримання конфіденційної інформації. Адже як-не-як, для звичайної пошукової системи Google, такий процес збору інформації може виявитися досить цікавим.
Пошук бюджетів на веб-сайті Міністерства національної безпеки та кібербезпеки США.
Наступна комбінація надає всі загальнодоступні проіндексовані таблиці Excel, що містять слово "бюджет":

бюджетний тип файлу: xls
Оскільки оператор filetype: автоматично не розпізнає різні версії однакових форматів файлів (наприклад, doc проти odt або xlsx проти csv), кожен з цих форматів повинен бути розбитий окремо:

бюджетний тип файлу:xlsx АБО тип файлу бюджету:csv
Наступний dork поверне PDF-файли на веб-сайті NASA:

сайт: nasa.gov Тип файлу: pdf
Ще один цікавий приклад використання дорка з ключовим словом «бюджет» — це пошук документів із кібербезпеки США у форматі «pdf» на офіційному сайті Міністерства внутрішньої оборони.

бюджетний сайт кібербезпеки:dhs.gov тип файлу:pdf
Те саме застосування дорка, але цього разу пошуковик поверне електронні таблиці .xlsx, що містять слово «бюджет» на веб-сайті Міністерства внутрішньої безпеки США:

бюджетний сайт: dhs.gov Тип файлу: xls
Пошук паролів
Пошук інформації з логіну та паролю може бути корисним як пошук вразливостей на власному ресурсі. В інших випадках паролі зберігаються у документах загального доступу на веб-серверах. Можна спробувати застосувати такі комбінації у різних пошукових системах:

пароль тип файлу: doc / docx / pdf / xls
пароль тип файлу: doc / docx / pdf / xls сайт: [Назва сайту]
Якщо спробувати ввести такий запит в іншій пошуковій системі, можна отримати абсолютно різні результати. Наприклад, якщо виконати цей запит без терміна "site: [Найменування сайту] ", Google поверне результати документів, що містять реальні імена користувачів та паролі деяких американських середніх шкіл. Інші пошукові системи не показують цієї інформації на перших сторінках результатів. Як це можна побачити нижче, Yahoo та DuckDuckGo є такими прикладами.


Ціни на житло у Лондоні
Інший цікавий приклад стосується інформації про ціну на житло у Лондоні. Нижче наведено результати запиту, який було введено у чотирьох різних пошукових системах:

тип файлу:xls «ціни житла» та «Лондон»
Можливо, тепер у вас є власні ідеї та уявлення про те, на яких веб-сайтах ви хотіли б зосередитися у своєму власному пошуку інформації або як правильно перевіряти свій власний ресурс на визначення можливих вразливостей.
Альтернативні інструменти пошуку індексацій
Існують також інші методи збору інформації за допомогою Google Dorking. Всі вони є альтернативою і виступають як автоматизація пошукових процесів. Нижче пропонуємо поглянути на одні з найпопулярніших проектів, якими можна поділитися.
Злом Google онлайн
Google Hacking Online — це онлайн інтеграція пошуку Google Dorking різних даних через веб-сторінку за допомогою встановлених операторів, з якими ви можете ознайомитися тут . Інструмент являє собою звичайне поле введення для пошуку бажаної IP адреси або URL посилання на ресурс, що цікавить, разом з пропонованими опціями пошуку.

Як видно з картинки вище, пошук за кількома параметрами надається у вигляді кількох варіантів:
Пошук публічних та вразливих каталогів
Файли конфігурації
Файли баз даних
Логи
Старі дані та дані резервного копіювання
Сторінки аутентифікації
Помилки SQL
Документи, що зберігаються у спільному доступі
Інформація про конфігурацію php на сервері (phpinfo)
Файли загального інтерфейсу шлюзу (CGI)
Все працює на ванільному JS, який прописаний у самому файлі веб-сторінки. На початку береться введена інформація користувача, а саме найменування хоста або IP-адреса веб-сторінки. І потім складається запит із операторами на введену інформацію. Посилання на пошук певного ресурсу відкривається в новому спливаючому вікні, з наданими результатами.
BinGoo

BinGoo - це універсальний інструмент, написаний на чистому bash. Він використовує пошукові оператори Google та Bing для фільтрації великої кількості посилань на основі наведених пошукових термінів. Можна вибрати пошук одного оператора за раз або скласти списки одного оператора на рядок і виконати масове сканування. Як тільки закінчується процес із початковим збором інформації або у вас з'являться посилання, зібрані іншими способами, можна перейти до інструментів аналізу, щоб перевірити загальні ознаки вразливостей.
Результати акуратно відсортовані у файлах на основі отриманих результатів. Але й тут аналіз не зупиняється, можна піти ще далі та запустити їх за допомогою додаткових функціоналів SQL або LFI або можна використовувати інструменти-оболонки SQLMAP та FIMAP, які працюють набагато краще, з точними результатами.
Також включено кілька зручних функцій, щоб спростити життя, таких як «геодоркінг» на основі типу домену, кодів країн в домені та перевірка загального хостингу, яка використовує попередньо налаштований пошук Bing та список доріжок для пошуку можливих вразливостей на інших сайтах. Також увімкнено простий пошук сторінок адміністраторів, що працює на основі наданого списку та кодів відповіді сервера для підтвердження. Загалом це дуже цікавий і компактний пакет інструментів, що здійснює основний збір та аналіз заданої інформації! Ознайомитись з ним можна ось тут .
пагода
Мета інструменту Pagodo – це пасивне індексування операторів Google Dorking для збору потенційно вразливих веб-сторінок та програм через Інтернет. Програма складається із двох частин. Перша – це ghdb_scraper.py, яка запитує та збирає оператори Google Dorks, а друга – pagodo.py, використовує оператори та інформацію, зібрану через ghdb_scraper.py та аналізує її через запити Google.
Для початку файлу pagodo.py потрібен список операторів Google Dorks. Подібний файл надається або в репозиторії самого проекту або можна запросити всю базу даних через один GET-запит, використовуючи ghdb_scraper.py. А потім просто скопіювати окремі оператори dorks в текстовий файл або помістити в json, якщо потрібні додаткові контекстні дані.
Для того, щоб зробити цю операцію, потрібно ввести таку команду:
python3 ghdb_scraper.py -j -s
Тепер, коли є файл з усіма потрібними операторами, його можна перенаправити в pagodo.py за допомогою опції «-g», щоб розпочати збір потенційно вразливих та загальнодоступних програм. Файл pagodo.py використовує бібліотеку «google» для пошуку таких сайтів за допомогою таких операторів:
intitle: «ListMail Login» адмін -демо
сайт: example.com
На жаль, процес настільки величезної кількості запитів (а саме ~ 4600) через Google просто не буде працювати. Google відразу ж визначить вас як бота та заблокує IP адресу на певний період. Для того щоб пошукові запити виглядали органічнішими, було додано кілька поліпшень.
Для модуля Python google зробили спеціальні поправки, щоб забезпечити рандомізацію агента користувача через пошукові запити Google. Ця функція доступна у версії модуля 1.9.3 і дозволяє рандомізувати різні агенти користувача, що використовуються для кожного пошукового запиту. Дана можливість дозволяє емулювати різні браузери, що використовуються у великому корпоративному середовищі.
Друге удосконалення фокусується на рандомізації часу між пошуковими запитами. Мінімальна затримка вказується за допомогою параметра -e, а коефіцієнт джиттера використовується для додавання часу до мінімального числа затримок. Створюється список з 50 джиттерів і один з них випадково додається до мінімального часу затримки для кожного процесу пошуку в Google.
self.jitter = numpy.random.uniform(low=self.delay, high=jitter * self.delay, size=(50,))
Далі у скрипті вибирається випадковий час із масиву джиттера та додається до затримки створення запитів:
pause_time = self.delay + random.choice (self.jitter)
Можна самостійно поекспериментувати зі значеннями, але налаштування за замовчуванням працюють таким чином успішно. Зверніть увагу, що процес роботи інструменту може зайняти кілька днів (в середньому 3; залежно від кількості заданих операторів та інтервалу запиту), тому переконайтеся, що у вас є час.
Щоб запустити сам інструмент, достатньо наступної команди, де «example.com» це посилання на веб-сайт, що цікавиться, а «dorks.txt» це текстовий файл який створив ghdb_scraper.py:
python3 pagodo.py -d example.com -g dorks.txt -l 50 -s -e 35.0 -j 1.1
І ви можете торкнутися і ознайомитися з самим інструментом, натиснувши це посилання .
Методи захисту від Google Dorking
Основні рекомендації
Google Dorking, як і будь-який інший інструмент вільного доступу, має свої техніки для захисту та запобігання збору конфіденційної інформації зловмисниками. Наступні рекомендації п'яти протоколів слід дотримуватися адміністраторам будь-яких веб-платформ і серверів, щоб уникнути загроз від Google Dorking:
Систематичне оновлення операційних систем, сервісів та додатків.
Впровадження та обслуговування анти-хакерських систем.
Поінформованість про Google роботах та різні процедури пошукових систем, а також способи перевірки таких процесів.
Видалення конфіденційного вмісту із загальнодоступних джерел.
Поділ загальнодоступного контенту, приватного контенту та блокування доступу до контенту для користувачів загального доступу.
Конфігурація файлів .htaccess та robots.txt
В основному всі вразливості та загрози, пов'язані з "Dorking", генеруються через неуважність або недбалість користувачів різних програм, серверів або інших веб-пристроїв. Тому правила самозахисту та захисту даних не викликають жодних утруднень чи ускладнень.
Для того, щоб ретельно підійти до запобігання індексаціям з боку будь-яких пошукових систем, варто звернути увагу на два основних файли конфігурацій будь-якого мережного ресурсу: «.htaccess» і «robots.txt». Перший - захищає зазначені шляхи та директорії за допомогою паролів. Другий - виключає директорії з індексування пошукових систем.
У випадку, якщо на вашому власному ресурсі містяться певні види даних або директорій, яким не слід бути індексованим на Google, то насамперед слід налаштувати доступ до папок через паролі. На прикладі нижче, можна наочно подивитися як правильно і що саме слід прописати у файл ".htaccess", що знаходиться в кореневій директорії будь-якого веб-сайту.
Для початку слід додати кілька рядків, показані нижче:
AuthUserFile /your/directory/here/.htpasswd
AuthGroupFile / dev / null
AuthName «Захищений документ»
AuthType Basic
вимагати ім'я користувача1
вимагати ім'я користувача2
вимагати ім'я користувача3
У рядку AuthUserFile вказуємо шлях до розташування файлу .htaccess, який знаходиться у вашому каталозі. А в трьох останніх рядках потрібно вказати відповідне ім'я користувача, до якого буде надано доступ. Потім потрібно створити ".htpasswd" в тій же папці, що і ".htaccess" і виконавши наступну команду:
htpasswd -c .htpasswd ім'я користувача1
Двічі ввести пароль для користувача username1 і після цього буде створено абсолютно чистий файл «.htpasswd» у поточному каталозі і міститиме зашифровану версію пароля.
Якщо є кілька користувачів, слід призначити кожному паролі. Щоб додати додаткових користувачів, не потрібно створювати новий файл, можна просто додати їх до існуючого файлу, не використовуючи опцію -c, за допомогою цієї команди:
htpasswd .htpasswd ім'я користувача2
В інших випадках рекомендується налаштовувати файл robots.txt, який відповідає за індексацію сторінок будь-якого веб-ресурсу. Він є провідником для будь-якої пошукової системи, яка посилається на певні адреси сторінок. І перш ніж перейти безпосередньо до джерела, robots.txt буде або блокувати подібні запити, або пропускати їх.
Сам файл розташований у кореневому каталозі будь-якої веб-платформи, запущеної в Інтернеті. Конфігурація здійснюється лише зміною двох основних параметрів: «User-agent» і «Disallow». Перший виділяє та зазначає або всі, або якісь певні пошукові системи. У той час як другий зазначає, що потрібно заблокувати (файли, каталоги, файли з певними розширеннями і т.д.). Нижче наведено кілька прикладів: виключення каталогу, файлу та певної пошукової системи, виключені з процесу індексування.
Агент користувача: *
Заборонити: /cgi-bin/
Агент користувача: *
Заборонити: /~joe/junk.html
Користувач-агент: Bing
Заборонити: /
Використання мета-тегів
Також обмеження для мережевих павуків можуть бути введені на окремих веб-сторінках. Вони можуть бути розміщені як на типових веб-сайтах, блогах, так і сторінках конфігурацій. У заголовку HTML вони повинні супроводжуватися однією з наступних фраз:
При додаванні такого запису в хедері сторінки, роботи Google не індексуватимуть ні другорядні, ні головну сторінку. Цей рядок може бути введений на сторінках, яким не слід індексуватися. Однак це рішення засноване на обопільній угоді між пошуковими системами та самим користувачем. Хоча Google та інші мережеві павуки дотримуються вищезгаданих обмежень, є певні мережеві роботи «полюють» такі фрази для отримання даних, спочатку налаштованих без індексації.
З більш просунутих варіантів безпеки індексування, можна скористатися системою CAPTCHA. Це комп'ютерний тест, який дозволяє отримати доступ до контенту сторінки лише людям, а не автоматичним роботам. Однак цей варіант має невеликий недолік. Він дуже зручний для самих користувачів.
Іншим простим захисним методом від Google Dorks може бути, наприклад, кодування знаків в адміністративних файлах кодуванням ASCII, що ускладнює використання Google Dorking.
Практика пентестинга
Практика пентестингу - це тести на виявлення вразливостей в мережі та на веб-платформах. Вони важливі, тому що такі тести однозначно визначають рівень вразливості веб-сторінок або серверів, включаючи Google Dorking. Існують спеціальні інструменти для пентестів, які можна знайти в Інтернеті. Одним із них є Site Digger, сайт, що дозволяє автоматично перевіряти базу даних Google Hacking на будь-якій вибраній веб-сторінці. Також є ще такі інструменти, як сканер Wikto, SUCURI та різні інші онлайн-сканери. Вони працюють аналогічно.
Є більш серйозні інструменти, що імітують середовище веб-сторінки, разом з помилками та вразливістю для того, щоб заманити зловмисника, а потім отримати конфіденційну інформацію про нього, як, наприклад, Google Hack Honeypot. Стандартному користувачеві, у якого мало знань і недостатньо досвіду в захисті від Google Dorking, слід перевірити свій мережевий ресурс на виявлення вразливостей Google Dorking і перевірити які конфіденційні дані є загальнодоступними. Варто регулярно перевіряти такі бази даних, haveibeenpwned.com та dehashed.com , щоб з'ясувати, чи не було порушено та опубліковано безпеку ваших облікових записів у мережі.

https://haveibeenpwned.com/ , стосується погано захищених веб-сторінок, де були зібрані дані облікових записів (адреси електронної пошти, логіни, паролі та інші дані). В даний час база даних містить понад 5 мільярдів облікових записів. Більш просунутий інструмент доступний на https://dehashed.com , що дозволяє шукати інформацію за іменами користувачів, адресами електронних пошт, паролів та їх хешу, IP адресами, іменами та номерами телефонів. На додаток, рахунки, за якими стався витік даних, можна купити в мережі. Вартість одноденного доступу становить лише 2 долари США.
Висновок
Google Dorking є невід'ємною частиною процесу збирання конфіденційної інформації та процесу її аналізу. Його по праву можна вважати одним із самих кореневих та головних інструментів OSINT. Оператори Google Dorking допомагають як у тестуванні власного сервера, так і в пошуку всієї можливої інформації про потенційну жертву. Це справді дуже яскравий приклад коректного використання пошукових механізмів для розвідки конкретної інформації. Однак чи є наміри використання даної технології добрими (перевірка вразливостей власного інтернет ресурсу) або недобрими (пошук та збирання інформації з різноманітних ресурсів та використання її в незаконних цілях) залишається вирішувати лише самим користувачам.
Альтернативні методи та інструменти автоматизації дають ще більше можливостей та зручностей для аналізу веб ресурсів. Деякі з них, наприклад BinGoo, розширює звичайний індексований пошук на Bing і аналізує всю отриману інформацію через додаткові інструменти (SqlMap, Fimap). Вони в свою чергу подають більш точну та конкретну інформацію про безпеку обраного веб ресурсу.
У той же час, важливо знати і пам'ятати як правильно убезпечити і запобігти своїм онлайн платформи від процесів індексування, там де вони не повинні бути. А також дотримуватися основних положень, передбачених для кожного веб-адміністратора. Адже незнання і неусвідомлення того, що за своєю помилкою, твою інформацію придбали інші люди, ще не означає те, що все можна повернути як було раніше.
:extract_focal()/https%3A%2F%2Flegalinform.org%2Fwp-content%2Fuploads%2F2021%2F08%2Fvultur.jpg)
:extract_focal()/https%3A%2F%2Flegalinform.org%2Fwp-content%2Fuploads%2F2021%2F08%2Ffedorov_vultur.jpg)


 Як ви вже здогадалися дана віртуальна машина покликана підвищити рівень анонімності і конфіденційності при використанні дистрибутива CSI Linux Analyst.
Як ви вже здогадалися дана віртуальна машина покликана підвищити рівень анонімності і конфіденційності при використанні дистрибутива CSI Linux Analyst.